1. Problem Statement
The orchestration challenge: Single-agent AI systems fail at complex software development because:
- Context overload — one agent can't hold requirements, architecture, code, tests, and documentation in context simultaneously
- Specialization gap — security review requires different expertise than UI design or database optimization
- Quality drift — without checkpoints, agents produce placeholder code, skip tests, and violate requirements
- Scope creep — agents add features not in the spec or ignore critical requirements
- Intent misalignment — agents optimize for speed when you wanted security, or vice versa
Multi-agent orchestration solves this by decomposing work into specialized agents with formal handoffs, quality gates, and requirement tracing. Instead of one overwhelmed agent, you get a coordinated team where each agent has a clear role, deliverables, and verification criteria.
2. Architecture Overview
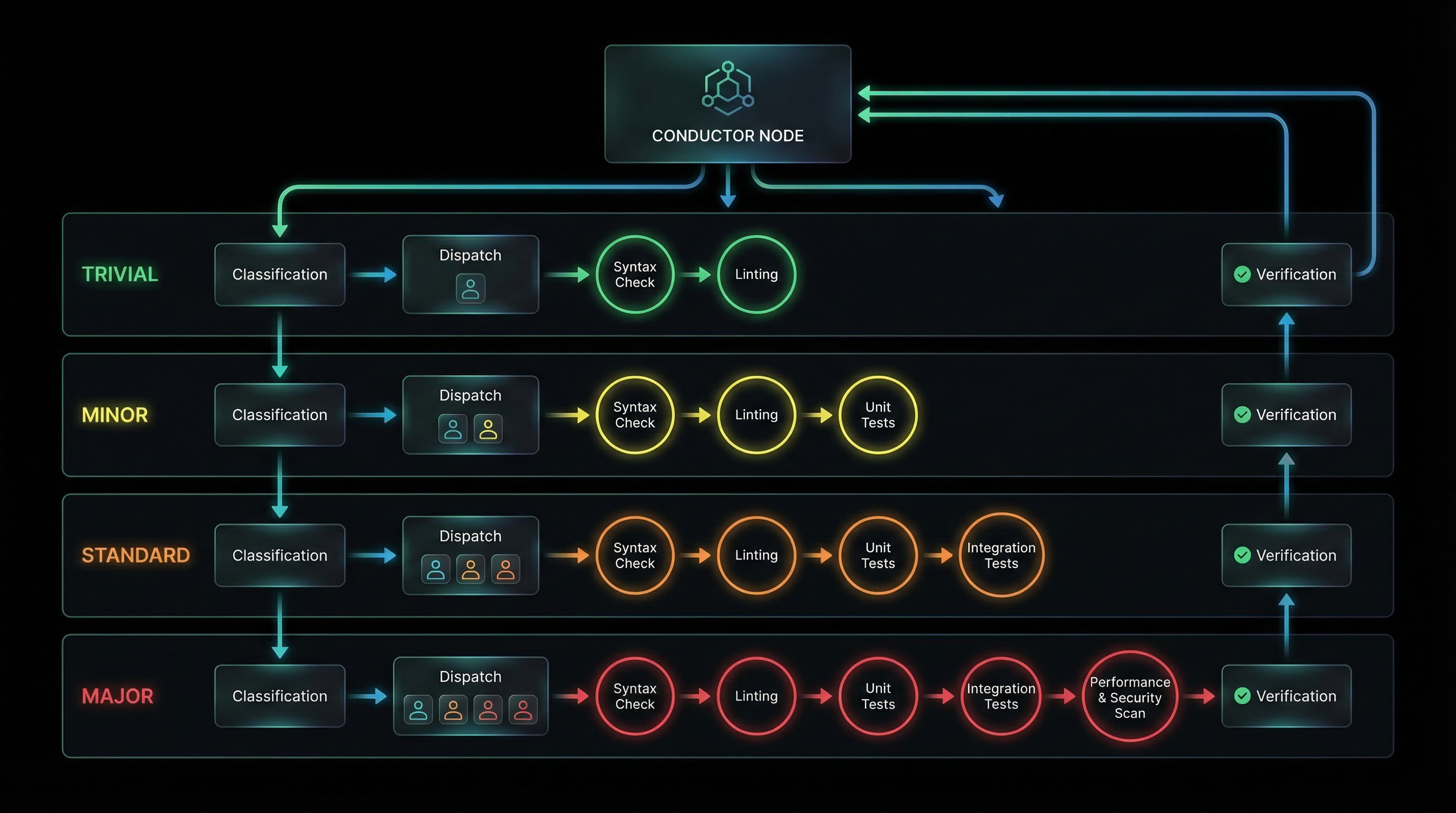
3. Key Components
3.1 Five-Signal Tier Classification
Every task is classified into TRIVIAL, MINOR, STANDARD, or MAJOR tier using a weighted 5-signal matrix:
| Signal | Weight | What It Measures | 1 (Low) | 4 (High) |
|---|---|---|---|---|
| scope | 30% | How many components affected | Single file tweak | Multi-service platform |
| type | 25% | Nature of work | Bug fix | Greenfield system |
| risk | 25% | Blast radius of failure | Dev-only change | Production auth system |
| ambiguity | 20% | Clarity of requirements | Exact spec provided | Vague description |
| intent_sensitivity | 25% | How closely task touches intent objectives or hard limits | Cosmetic change | Core security decision |
Calculation: score = (scope × 0.30) + (type × 0.25) + (risk × 0.25) + (ambiguity × 0.20) + (intent_sensitivity × 0.25)
# Example: "Build a SaaS dashboard with Stripe integration"
scope = 3.5 # Multi-page app, API, database, payment integration
type = 3.0 # New feature in existing codebase
risk = 3.5 # Payment processing (PCI compliance, fraud risk)
ambiguity = 2.5 # Some details provided, but UX/design unclear
intent_sensitivity = 3.0 # Core product feature, revenue-critical
score = (3.5 × 0.30) + (3.0 × 0.25) + (3.5 × 0.25) + (2.5 × 0.20) + (3.0 × 0.25)
= 1.05 + 0.75 + 0.875 + 0.5 + 0.75
= 3.925 → MAJOR tier (3.3-4.0)Why intent_sensitivity matters: A simple CSS change (scope=1) normally scores TRIVIAL. But if it's changing the color of a security warning that users must notice, intent_sensitivity=4, escalating the tier to ensure proper review.
3.2 Tiered Workflow Templates
Each tier uses a different workflow. Higher tiers add more phases and stricter gates.
TRIVIAL Tier (1.0-1.5)
analyze-codebase → conductor-builder(plan-and-implement) → verifyCharacteristics: Single agent, no critic gates, no BRD extraction. For quick fixes and cosmetic changes.
MINOR Tier (1.6-2.3)
analyze-codebase → conductor-builder(plan) → conductor-builder(implement)
→ conductor-ciso(advisory) → conductor-critic(advisory) → verify
→ conductor-completeness-validator(advisory)Characteristics: Split planning/implementation, advisory-only gates (log findings but don't block).
STANDARD Tier (2.4-3.2)
conductor-project-setup → conductor-research → conductor-ciso(requirements)
→ CRITIC(post-ciso, advisory) → BRD-EXTRACTION → CRITIC(post-extraction, advisory)
→ [conductor-architect + api-design + database] → CRITIC(post-architect, advisory)
→ conductor-qa → CRITIC(post-qa, advisory) → conductor-builder(implement)
→ conductor-ciso(code-review) → [code-reviewer + qa + performance + compliance]
→ CRITIC(post-implementation, advisory) → FINAL-BRD-VERIFICATION
→ pentest-coordinator → CRITIC(post-pentest, BLOCKING)
→ CRITIC(pre-release, BLOCKING) → conductor-doc-gen → api-docs
→ devops → observability → conductor-completeness-validator(BLOCKING)Characteristics: Full workflow, most gates advisory, PRE-RELEASE and COMPLETENESS gates BLOCKING. Pentest required.
MAJOR Tier (3.3-4.0)
Same as STANDARD, but ALL gates are BLOCKING.Characteristics: Every checkpoint must pass before progression. Maximum scrutiny.
3.3 Quality Gate Matrix
Quality gates are checkpoints where the conductor-critic agent validates deliverables. Gates can be:
- BLOCKING — workflow stops until issue resolved
- ADVISORY — findings logged, workflow continues
- SKIP — gate not executed (TRIVIAL tier only)
| Gate | TRIVIAL | MINOR | STANDARD | MAJOR |
|---|---|---|---|---|
| POST-CISO | skip | advisory | advisory | BLOCKING |
| POST-BRD-EXTRACTION | skip | advisory | advisory | BLOCKING |
| POST-ARCHITECT | skip | advisory | advisory | BLOCKING |
| POST-QA | skip | skip | advisory | BLOCKING |
| POST-IMPLEMENTATION | skip | advisory | advisory | BLOCKING |
| PRE-RELEASE | skip | skip | BLOCKING | BLOCKING |
| POST-PENTEST | skip | skip | BLOCKING | BLOCKING |
| COMPLETENESS | skip | advisory | BLOCKING | BLOCKING |
Critical insight: PRE-RELEASE and COMPLETENESS gates are ALWAYS blocking in STANDARD+ tiers. This ensures no half-finished implementations or broken deployments.
3.4 BRD-Driven Development
Every project starts with a Business Requirements Document (BRD). The workflow ensures 100% BRD traceability:
- Requirements gathering — conductor-research agent creates BRD with numbered requirements (REQ-001, REQ-002, ...)
- BRD extraction (MANDATORY BLOCKING GATE) — every requirement extracted to BRD-tracker.json:
{ "requirements": [ { "id": "REQ-001", "description": "User can log in with email/password", "category": "functional", "priority": "critical", "acceptance_criteria": ["...", "..."], "status": "pending", "todo_file": null, "is_placeholder": false } ] } - Specification decomposition — conductor-architect creates TODO spec for each requirement, links in BRD-tracker.json
- Implementation tracking — conductor-builder updates status: pending → in_progress → implemented → tested → complete
- Final verification (MANDATORY BLOCKING GATE) — 100% requirements must be "complete" before release
is_placeholder: false validation.
3.5 Agent Capability Routing
The conductor uses a capability matrix to route tasks to the right agent. Each agent declares:
- accepts — task types this agent can handle
- produces — artifacts this agent generates
- requires — dependencies that must exist before handoff
- constraints — rules this agent must follow
- intent_constraints — how this agent respects intent objectives and hard limits
Example: conductor-builder capability
conductor-builder:
accepts:
- specification
- bug_fix_request
- implementation_task
produces:
- code
- tests
- updated_brd_tracker
requires:
- TODO_spec_file
- BRD-tracker.json
constraints:
- "No stub implementations"
- "Must update BRD-tracker status"
intent_constraints:
- "Must respect trade-off resolutions when making implementation decisions"
- "Must check delegation_boundaries before executing"
- "Must never violate hard_limits"Handoff validation: Before dispatching, conductor checks:
if not (source.produces ⊆ target.accepts):
error("Handoff invalid: source doesn't produce what target accepts")
if not (target.requires ⊆ available_artifacts):
error("Missing dependencies: {target.requires - available_artifacts}")This turns agent orchestration into a type-checked workflow.
3.6 Intent Engineering
Intent engineering solves the "agent guesses wrong trade-off" problem. Instead of hoping the agent picks the right balance (speed vs security, simplicity vs features), you declare intent upfront.
The intent block in conductor-state.json has four sections:
1. Objectives (what success looks like)
"objectives": [
"Production-ready authentication with MFA",
"WCAG AA accessibility compliance",
"Sub-200ms API response times"
]2. Trade-offs (resolved upfront)
"trade_offs": [
{
"decision": "Security over speed",
"rationale": "Financial data - compliance is non-negotiable",
"implications": ["May sacrifice some UX convenience for MFA"]
},
{
"decision": "Simplicity over features",
"rationale": "MVP launch in 6 weeks",
"implications": ["Defer advanced analytics to v2"]
}
]3. Delegation boundaries (what requires human approval)
"delegation_boundaries": {
"autonomous": [
"Code implementation within approved specs",
"Test generation",
"Documentation"
],
"human_in_loop": [
"Architecture decisions affecting >3 components",
"Third-party API selection",
"Database schema changes"
]
}4. Hard limits (never violate these)
"hard_limits": [
"No GPL dependencies in proprietary code",
"No API keys in code or config files",
"No unauthenticated routes to PII",
"Max bundle size 500KB (gzip)",
"Zero OWASP Top 10 violations"
]Intent-aware agent behavior
Agents with intent_constraints in the capability matrix:
- Check trade-offs before decisions — "User wants security over speed, so I'll use bcrypt with cost=12 instead of MD5"
- Respect delegation boundaries — "This architectural change requires human approval, pausing for review"
- Never violate hard limits — "Hard limit says no GPL, rejecting this MIT+GPL dual-licensed library"
- Log intent alignment — Every decision logged with rationale referencing intent objectives
Critic validation of intent alignment
At every checkpoint, conductor-critic validates:
# POST-IMPLEMENTATION gate
findings = []
# Check hard_limit violations (always BLOCKING)
if uses_gpl_library(code) and "No GPL" in hard_limits:
findings.append({
"severity": "CRITICAL",
"type": "HARD_LIMIT_VIOLATION",
"message": "GPL library detected",
"blocking": True # regardless of tier
})
# Check trade-off compliance
if trade_off == "Security over speed" and uses_weak_hash(code):
findings.append({
"severity": "HIGH",
"type": "TRADE_OFF_VIOLATION",
"message": "Weak hashing contradicts security priority"
})
# Check delegation boundary violations
if architectural_change and not has_approval:
findings.append({
"severity": "HIGH",
"type": "DELEGATION_VIOLATION",
"message": "Architecture change requires human approval"
})Hard limit violations escalate tier. A TRIVIAL task (score=1.2) that touches a hard limit (e.g., "No unauthenticated PII routes") auto-escalates to STANDARD tier (minimum) for blocking gates.
3.7 State Persistence (conductor-state.json)
The workflow survives session restarts via conductor-state.json. Schema excerpt:
{
"project_name": "saas-dashboard",
"initiated_at": "2026-03-17T10:00:00Z",
"last_updated": "2026-03-17T14:32:15Z",
"tier": "MAJOR",
"tier_score": 3.925,
"tier_signals": {
"scope": 3.5,
"type": 3.0,
"risk": 3.5,
"ambiguity": 2.5,
"intent_sensitivity": 3.0
},
"current_phase": {
"number": 3,
"name": "Implementation",
"started_at": "2026-03-17T12:00:00Z"
},
"current_step": {
"number": 11,
"name": "Code Generation",
"assigned_agent": "conductor-builder",
"status": "in_progress"
},
"intent": {
"objectives": ["..."],
"trade_offs": [...],
"delegation_boundaries": {...},
"hard_limits": [...]
},
"task_queue": [
{
"id": "task-042",
"agent": "conductor-builder",
"prompt": "Implement TODO/feature-payment.md",
"status": "pending"
}
],
"completed_tasks": [...],
"verification_status": {
"extraction_complete": true,
"specs_complete": true,
"post_ciso_passed": true,
"post_architect_passed": false,
"gate_failures": [
{
"gate": "POST-ARCHITECT",
"reason": "Missing API error handling spec",
"timestamp": "2026-03-17T11:45:00Z"
}
]
}
}Recovery: /conduct resume reads state, verifies no steps were skipped, continues from current_step.
3.8 Completeness Validation (12 Domains)
The conductor-completeness-validator agent runs exhaustive checks across 12 domains:
| Domain | What It Checks |
|---|---|
| Dependencies | Every import resolves, no missing packages |
| Dead Code | No orphan files, unused functions |
| Configuration | All env vars defined, no hardcoded secrets |
| Links | All internal links resolve, external links reachable |
| Assets | All referenced images/fonts/files exist |
| Build | Build succeeds with zero errors |
| Tests | Full test suite passes |
| Routes | Every route returns valid response (not 500) |
| API | Every endpoint responds correctly |
| UI | Pages load without console errors (if applicable) |
| Containers | Health checks pass (if containerized) |
| BRD Traceability | 100% requirements marked complete |
Output: completeness-report-<timestamp>.json with verdict (PASS/FAIL) and findings per domain.
When it runs: Phase 7 (after all code changes). In STANDARD+ tier, BLOCKING gate — workflow cannot complete until PASS.
3.9 Adversarial Dual-AI Review
The conductor-qa-review agent runs multi-model consensus reviews at checkpoints:
- Claude Opus 4.6 — primary reviewer
- Google Gemini 2.0 — adversarial perspective
- OpenAI GPT-4o — tie-breaker (if available)
Consensus logic:
# Example: Code quality review
claude_findings = ["Weak input validation in auth.js", "No rate limiting"]
gemini_findings = ["Weak input validation in auth.js", "Missing error logging"]
codex_findings = ["Weak input validation in auth.js"]
# Consensus: 3/3 agree on input validation → CRITICAL
# Split: 1/3 on rate limiting → escalate to user decision
# Split: 1/3 on error logging → escalate to user decision
consensus_report = {
"critical": ["Weak input validation in auth.js"],
"escalated": [
{"finding": "No rate limiting", "votes": 1, "requires_review": true},
{"finding": "Missing error logging", "votes": 1, "requires_review": true}
]
}Escalation rule: If 1/3 models flag CRITICAL and others don't, escalate to user. Never auto-dismiss.
Profile selection by tier:
- TRIVIAL: quick profile (single-pass, no consensus)
- MINOR/STANDARD: standard profile (2-model consensus)
- MAJOR: thorough profile (3-model consensus + adversarial prompts)
3.10 Code Hardener Integration
After implementation, the code-hardener agent runs automated security fixes:
- SAST scan (Semgrep, Bandit, ESLint security rules)
- Secret detection (TruffleHog, detect-secrets)
- Dependency vulnerability scan (npm audit, safety, Snyk)
- Auto-fix safe issues (unused imports, weak crypto → strong crypto)
- Generate TODO specs for complex issues requiring human review
# Example hardener output
{
"auto_fixed": [
{"file": "auth.js", "issue": "MD5 hash", "fix": "Replaced with bcrypt"},
{"file": "config.js", "issue": "Hardcoded API key", "fix": "Moved to .env"}
],
"requires_review": [
{
"file": "payment.js",
"issue": "SQL injection risk in dynamic query",
"todo_file": "TODO/security-payment-sqli.md",
"severity": "CRITICAL"
}
]
}Integration point: Runs in Phase 3 after conductor-builder, before conductor-critic POST-IMPLEMENTATION gate. Ensures security issues caught before final review.
4. Requirements
5. Prompt to Build It
Build a multi-agent orchestration system for software development with tier-based workflows, quality gates, and intent engineering. Create a "conductor" plugin with the following:
**1. Tier Classification System**
- 5-signal weighted matrix: scope (30%), type (25%), risk (25%), ambiguity (20%), intent_sensitivity (25%)
- Score range 1.0-4.0 maps to TRIVIAL/MINOR/STANDARD/MAJOR tiers
- Auto-escalate tier when task touches hard_limits
- Create tier-classifier.py that accepts task description, returns tier + signal breakdown
**2. Workflow Templates**
- Create workflow-templates.yaml with phase sequences for each tier
- TRIVIAL: single agent, no gates
- MINOR: split plan/implement, advisory gates
- STANDARD: full workflow, PRE-RELEASE and COMPLETENESS blocking
- MAJOR: all gates blocking
- Each template defines: phases, agents, gates (with mode: blocking/advisory/skip)
**3. BRD-Driven Development**
- Create BRD-tracker.json schema: id, description, category, status, todo_file, is_placeholder
- conductor-research agent generates BRD with numbered requirements
- BRD extraction (MANDATORY BLOCKING GATE) extracts all to BRD-tracker.json
- conductor-architect creates TODO specs, links in BRD-tracker
- conductor-builder updates status: pending → implemented → tested → complete
- Final verification gate: 100% requirements must be "complete"
**4. Intent Engineering**
- Extend conductor-state.json schema with intent block:
- objectives (array of strings)
- trade_offs (array of {decision, rationale, implications})
- delegation_boundaries ({autonomous: [...], human_in_loop: [...]})
- hard_limits (array of strings)
- conductor-critic validates at every checkpoint:
- hard_limit violations → always BLOCKING
- trade_off compliance → log findings
- delegation_boundary violations → escalate
- Agents with intent_constraints check before decisions, log rationale
**5. Agent Capability Matrix**
- Create capabilities.yaml with 14 core agents:
- conductor (orchestrator, model: opus[1m])
- conductor-research (requirements, model: sonnet)
- conductor-ciso (security, model: opus)
- conductor-architect (design, model: opus)
- conductor-builder (implementation, model: opus)
- conductor-qa (testing, model: sonnet)
- conductor-critic (validation, model: opus)
- conductor-code-reviewer (quality, model: sonnet)
- conductor-completeness-validator (artifact checks, model: opus)
- conductor-doc-gen (documentation, model: sonnet)
- conductor-devops (CI/CD, model: sonnet)
- conductor-performance (load tests, model: sonnet)
- conductor-compliance (SBOM, licenses, model: sonnet)
- conductor-qa-review (adversarial review, model: opus)
- Each agent defines: accepts, produces, requires, constraints, intent_constraints
- Handoff validation: source.produces ⊆ target.accepts, target.requires ⊆ available_artifacts
**6. Quality Gate System**
- Create quality-gates.yaml defining 8 gates:
- POST-CISO (STRIDE, OWASP coverage)
- POST-BRD-EXTRACTION (100% requirements captured)
- POST-ARCHITECT (100% BRD-to-spec mapping)
- POST-QA (test coverage validation)
- POST-IMPLEMENTATION (no placeholders)
- PRE-RELEASE (comprehensive readiness check)
- POST-PENTEST (findings remediated)
- COMPLETENESS (12-domain artifact validation)
- Each gate has mode matrix (tier → blocking/advisory/skip)
- conductor-critic agent executes gates, returns verdict + findings
**7. Completeness Validator**
- conductor-completeness-validator agent checks 12 domains:
- Dependencies (all imports resolve)
- Dead code (no orphan files)
- Configuration (all env vars defined)
- Links (internal resolve, external reachable)
- Assets (all referenced files exist)
- Build (succeeds with 0 errors)
- Tests (full suite passes)
- Routes (all return valid responses)
- API (all endpoints respond)
- UI (pages load without console errors)
- Containers (health checks pass)
- BRD traceability (100% complete)
- Output: completeness-report-.json with verdict + findings
**8. Adversarial Review**
- conductor-qa-review agent with multi-model consensus:
- Claude Opus 4.6 (primary)
- Google Gemini 2.0 (adversarial)
- OpenAI GPT-4o (tie-breaker if available)
- Consensus logic: 3/3 agree → CRITICAL, 1/3 → escalate to user
- Profile selection by tier: quick/standard/thorough
- Never auto-dismiss 1/3 CRITICAL findings
**9. State Persistence**
- conductor-state.json schema with:
- project_name, tier, tier_score, tier_signals
- current_phase, current_step
- task_queue, completed_tasks
- verification_status (gates passed/failed)
- intent block
- BRD progress
- SessionStart hook injects status if state exists
- PostToolUse hook validates state against schema
**10. Commands**
- /conduct command with argument routing:
- new → tier classification, create state, begin workflow
- resume → read state, continue from current_step
- status → comprehensive status display
- reset → delete state
- validate → run completeness-validator
**Deliverables:**
- Complete conductor plugin with all agents, skills, commands
- Tier classification system with 5-signal matrix
- BRD-tracker.json schema and extraction workflow
- Intent engineering with 4-section intent block
- Quality gate system with mode matrix
- Completeness validator checking 12 domains
- Adversarial review with multi-model consensus
- State persistence with recovery
- Working /conduct command with full workflow orchestration 6. Design Decisions
6.1 Why Tiered Workflows Instead of One-Size-Fits-All?
A CSS color change and a payment processing system need different rigor levels. One-size-fits-all means:
- Over-engineering trivial tasks — running pentest on a typo fix wastes time
- Under-engineering critical tasks — skipping security review on auth changes causes breaches
Tiered workflows solve this by matching rigor to risk. The 5-signal matrix ensures objective classification.
6.2 Why Intent Engineering Over Implicit Optimization?
Without explicit intent, agents guess trade-offs:
- "Should I optimize for speed or security?" — agent guesses speed, introduces vulnerability
- "Should I add this feature?" — agent adds scope creep
- "Can I change this architecture?" — agent breaks system without approval
Intent engineering declares upfront what matters. Agents don't guess, they consult intent block. Misalignment detected at gates, not in production.
6.3 Why BRD Extraction as MANDATORY BLOCKING GATE?
Without forced extraction, agents:
- Infer requirements from vague descriptions — build wrong thing
- Skip "obvious" requirements — forget error handling, accessibility
- Lose traceability — can't prove all requirements implemented
The blocking gate ensures 100% requirements captured before any design work. No progression until BRD-tracker.json complete.
6.4 Why Capability Matrix Over Ad-Hoc Task Passing?
Without capability validation, you get:
- Type mismatches — architect produces "page_mockups", builder expects "specification"
- Missing dependencies — dispatch agent before BRD exists
- Ignored constraints — builder produces placeholder code despite "no stubs" constraint
The capability matrix turns orchestration into a type-checked workflow. Handoffs validated at dispatch, not at failure.
6.5 Why Adversarial Multi-Model Review?
Single-model review has blind spots:
- Model biases — Claude might miss SQL injection patterns Gemini catches
- Overconfidence — single model says "looks good", ships with bugs
Multi-model consensus provides defense in depth. If 3/3 agree it's safe, high confidence. If 1/3 flags CRITICAL, escalate — never auto-dismiss.
6.6 Why Completeness Validator in Phase 7?
Agents claim "done" but:
- Imports don't resolve (dev machine had package installed globally)
- Links broken (forgot to update nav after renaming page)
- Tests pass but app crashes on startup (missing env var)
Completeness validator is the "does it actually work" gate. Runs after all code changes, checks 12 domains, blocking in STANDARD+ tier.
6.7 Why State Persistence?
Software projects take days/weeks. Without state:
- Session restart = start over — lose all progress
- Can't resume from checkpoint — re-run completed phases
- No audit trail — can't prove which gates passed
State persistence in conductor-state.json enables resume from any step. Workflow survives network failures, session timeouts, even machine reboots.
7. Integration Points
7.1 With Plugin Ecosystem
Conductor is a Claude Code plugin. It uses:
- SessionStart hook — injects workflow state if conductor-state.json exists
- PostToolUse hook — validates conductor-state.json against schema after writes
- Skills — workflow-reference skill provides tier templates and phase workflows
- Commands — /conduct command is user entry point
7.2 With Memory Systems
Conductor integrates with memory plugins for:
- Procedure storage — save successful workflows as reusable procedures
- Learning extraction — capture agent improvements from retrospective analysis
- Pattern recognition — detect when current task matches known patterns
# After successful workflow completion
memory_store(
type="procedure",
content=f"STANDARD tier workflow for {project_type}",
metadata={"tier": "STANDARD", "phases": 7, "duration_hours": 18}
)7.3 With Governance Systems
Governance plugins enforce compliance during orchestration:
- Approval gates — block external communication (e.g., email stakeholders) until user approves
- Data classification — prevent processing third-party data without classification
- Audit logging — log every agent dispatch, gate verdict, state transition
7.4 With Code Hardener
Code hardener runs in Phase 3 after conductor-builder:
# Phase 3 sequence
conductor-builder(implement) → code-hardener → conductor-ciso(code-review)
→ [code-reviewer + qa] → CRITIC(post-implementation)Hardener auto-fixes safe issues (weak crypto → strong crypto). Complex issues generate TODO specs routed back to conductor-builder.
7.5 With Testing Infrastructure
Testing runs at multiple checkpoints:
- Phase 2 — conductor-qa creates test plan and executable tests
- Phase 3 — conductor-qa executes tests after implementation
- Phase 7 — completeness-validator verifies full test suite passes
Tests stored in git, run in Docker container (testing-security-stack) for isolation.
7.6 With CI/CD Pipelines
Phase 6 (deployment) integrates with CI/CD:
- conductor-devops generates GitHub Actions workflows
- Multi-stage Docker builds with non-root user, resource limits
- Smoke tests on staging before production deployment
- conductor-observability sets up Prometheus + Grafana dashboards
Summary
Multi-agent orchestration transforms software development from single overwhelmed agent to coordinated specialist team:
- Tier classification matches rigor to risk via 5-signal matrix
- BRD-driven development ensures 100% requirement traceability
- Intent engineering eliminates trade-off guessing
- Capability routing validates handoffs at dispatch
- Quality gates enforce verification at checkpoints
- Completeness validation catches what agents miss
- Adversarial review provides defense in depth
- State persistence enables resume from any step
The result: production-ready code with no placeholders, 100% test coverage, security validated, and every requirement proven complete.