2. Architecture Overview
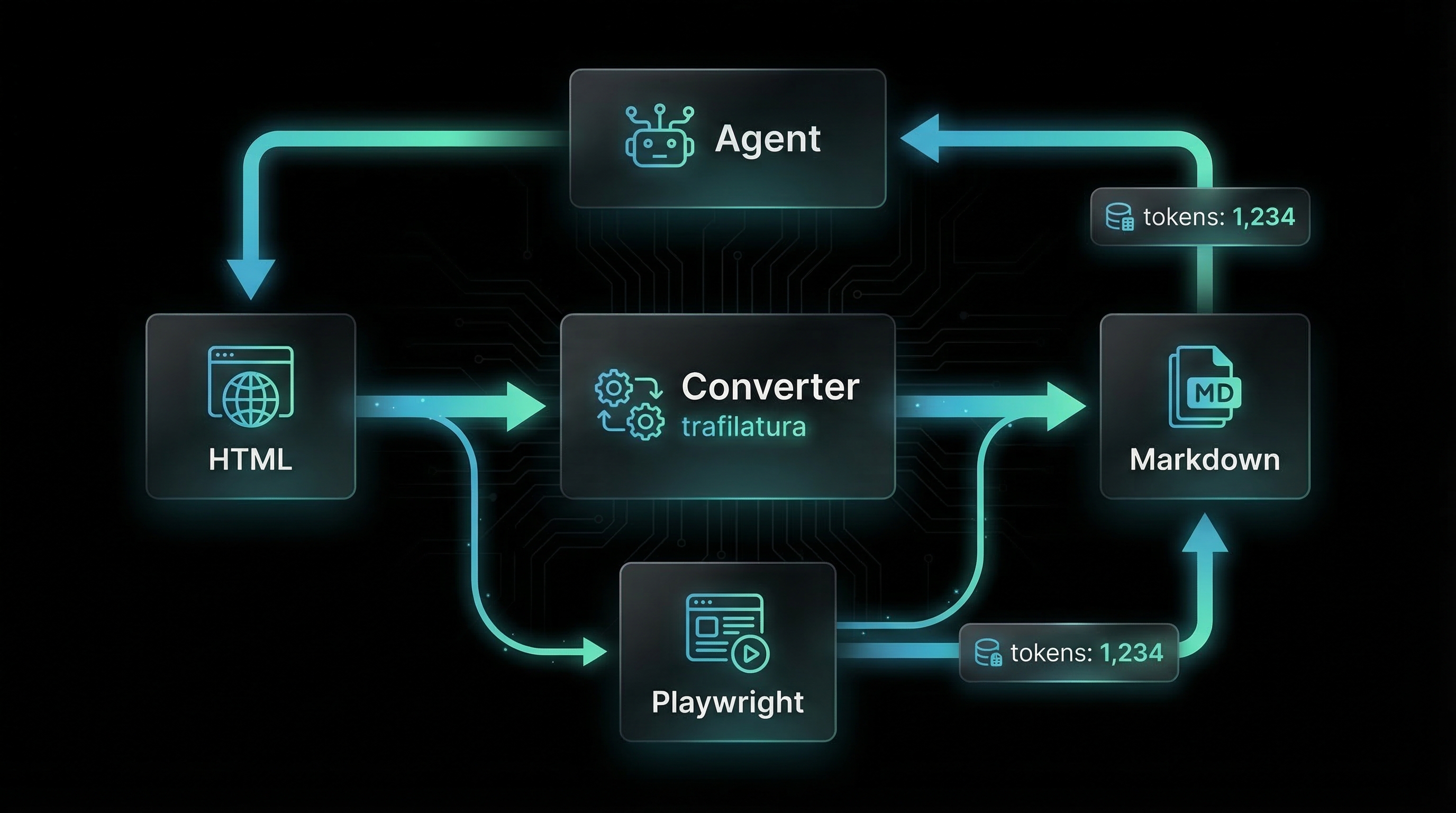
System Components
| Component |
Technology |
Responsibility |
| Proxy Server |
FastAPI (Python 3.12) |
HTTP request handling, routing, conversion orchestration |
| HTML Fetcher |
httpx (async) |
Download HTML content with user-agent spoofing, timeout enforcement |
| Content Extractor |
trafilatura |
Extract main content from HTML, remove boilerplate, convert to markdown |
| JS Renderer |
Playwright |
Execute JavaScript, wait for content load, screenshot capability |
| Token Counter |
tiktoken (cl100k_base) |
Estimate token count for context budget planning |
| Frontmatter Parser |
python-frontmatter |
Extract YAML metadata from markdown documents |
Conversion Pipeline (Progressive Enhancement):
- Native Markdown Detection: Check URL for
.md extension or Content-Type: text/markdown
- If native markdown found → Return as-is with frontmatter extraction
- Trafilatura Extraction: Fetch HTML, extract main content, convert to markdown
- If content meets minimum token threshold (30 tokens default) → Return with
x-markdown-source: trafilatura
- If content below threshold → Proceed to Playwright
- Playwright Rendering: Launch headless browser, execute JS, wait for content
- If rendered content meets threshold → Return with
x-markdown-source: playwright
- If timeout or error → Proceed to fallback
- Raw HTML Fallback: Return minimally cleaned HTML with warning header
x-markdown-source: fallback, content-signal: low
Three Deployment Modes
Mode 1: URL-Path Proxy (Agent-Friendly)
URL embedded in request path. Simplest for agent tool integration.
GET http://localhost:8090/https://example.com/article
→ Returns markdown conversion of example.com/article
# Agent tool call
curl http://localhost:8090/https://docs.docker.com/compose/
Mode 2: Header Proxy (Nginx Integration)
Original URL in path, proxy behavior triggered by Accept: text/markdown header. Enables nginx content negotiation.
GET https://example.com/article
Accept: text/markdown
→ Nginx proxies to localhost:8090, returns markdown
# Nginx config
location / {
if ($http_accept ~ "text/markdown") {
proxy_pass http://127.0.0.1:8090;
}
}
Mode 3: Sidecar (Local App Integration)
POST request with URL in JSON body. Used by local applications that need markdown conversion.
POST http://localhost:8090/convert
Content-Type: application/json
{"url": "https://example.com/article", "timeout": 15}
→ Returns JSON: {markdown, tokens, source, signal}
Response Headers
Every successful response includes metadata headers for agent decision-making:
| Header |
Values |
Purpose |
x-markdown-tokens |
Integer (e.g., 1247) |
Estimated token count for context budget planning |
x-markdown-source |
native | trafilatura | playwright | fallback |
Which conversion method succeeded |
content-signal |
high | medium | low |
Content quality indicator (high=native/trafilatura, medium=playwright, low=fallback) |
x-original-url |
URL string |
Original URL (useful when following redirects) |
x-conversion-time-ms |
Integer (milliseconds) |
Time taken for conversion (for performance monitoring) |
Agent Integration Example: Agent checks x-markdown-tokens header. If token count exceeds remaining context budget, agent can skip fetching the content or request a summary instead.
Configuration
Behavior controlled via environment variables:
# Size limits
MAX_HTML_BYTES=5242880 # 5MB max HTML download
MIN_CONTENT_TOKENS=30 # Minimum tokens to consider conversion successful
# Timeouts
REQUEST_TIMEOUT=15 # HTTP fetch timeout (seconds)
PLAYWRIGHT_TIMEOUT=20 # Browser rendering timeout (seconds)
PLAYWRIGHT_WAIT_FOR=networkidle # Wait condition: networkidle | load | domcontentloaded
# Behavior
USER_AGENT=Mozilla/5.0... # Browser user-agent string
ENABLE_PLAYWRIGHT=true # Disable to skip Playwright fallback
CACHE_TTL=3600 # Redis cache TTL for converted content (seconds)
BIND_HOST=127.0.0.1 # Localhost-only binding
BIND_PORT=8090 # Proxy listen port
3. Key Components
URL-Path Proxy Handler (GET /{url:path})
Main endpoint for agent consumption. URL embedded in path after leading slash.
@app.get("/{url:path}")
async def proxy_url(url: str):
# Extract URL from path (e.g., "/https://example.com" → "https://example.com")
if not url.startswith(("http://", "https://")):
url = "https://" + url
# Check cache (Redis)
cached = await get_cached_markdown(url)
if cached:
return Response(cached["markdown"], headers=cached["headers"])
# Run conversion pipeline
result = await convert_to_markdown(url)
# Cache result
await cache_markdown(url, result)
return Response(
content=result["markdown"],
media_type="text/markdown",
headers={
"x-markdown-tokens": str(result["tokens"]),
"x-markdown-source": result["source"],
"content-signal": result["signal"],
"x-original-url": url,
"x-conversion-time-ms": str(result["time_ms"])
}
)
Example Usage:
# Agent tool integration
import httpx
async def fetch_as_markdown(url: str) -> dict:
proxy_url = f"http://localhost:8090/{url}"
async with httpx.AsyncClient() as client:
response = await client.get(proxy_url)
return {
"content": response.text,
"tokens": int(response.headers["x-markdown-tokens"]),
"source": response.headers["x-markdown-source"],
"signal": response.headers["content-signal"]
}
result = await fetch_as_markdown("https://docs.python.org/3/library/asyncio.html")
print(f"Fetched {result['tokens']} tokens via {result['source']}")
Conversion Pipeline (convert_to_markdown())
Core logic that implements progressive enhancement with fallback chain.
async def convert_to_markdown(url: str) -> dict:
start_time = time.time()
# Step 1: Try native markdown
if url.endswith(".md") or url.endswith(".markdown"):
result = await fetch_native_markdown(url)
if result:
return finalize_result(result, "native", "high", start_time)
# Step 2: Fetch HTML
html = await fetch_html(url)
if not html:
return error_result("Failed to fetch URL", start_time)
# Step 3: Try trafilatura extraction
markdown = extract_with_trafilatura(html)
tokens = count_tokens(markdown)
if tokens >= MIN_CONTENT_TOKENS:
return finalize_result(markdown, "trafilatura", "high", start_time)
# Step 4: Try Playwright rendering (if enabled)
if ENABLE_PLAYWRIGHT:
markdown = await render_with_playwright(url)
tokens = count_tokens(markdown)
if tokens >= MIN_CONTENT_TOKENS:
return finalize_result(markdown, "playwright", "medium", start_time)
# Step 5: Fallback to raw HTML
markdown = clean_raw_html(html)
return finalize_result(markdown, "fallback", "low", start_time)
Trafilatura Extraction
Uses trafilatura library to extract main content from HTML, removing boilerplate, ads, and navigation.
import trafilatura
def extract_with_trafilatura(html: str) -> str:
# Extract main content
markdown = trafilatura.extract(
html,
output_format="markdown",
include_comments=False,
include_tables=True,
include_images=True,
include_links=True,
no_fallback=False
)
if not markdown:
return ""
# Clean up common artifacts
markdown = markdown.strip()
markdown = re.sub(r'\n{3,}', '\n\n', markdown) # Collapse excessive newlines
markdown = re.sub(r'\[!\[.*?\]\(.*?\)\]\(.*?\)', '', markdown) # Remove image links
return markdown
Why Trafilatura?
- Designed specifically for content extraction (vs general HTML parsing)
- Handles diverse HTML structures (blogs, news, documentation)
- Maintains semantic structure (headings, lists, tables)
- Built-in markdown output (no manual conversion needed)
Playwright Rendering
Launches headless Chromium browser to execute JavaScript and wait for content to load. Handles single-page apps and lazy-loaded content.
from playwright.async_api import async_playwright
import trafilatura
async def render_with_playwright(url: str) -> str:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page(
user_agent=USER_AGENT,
viewport={"width": 1920, "height": 1080}
)
try:
# Navigate and wait for content
await page.goto(url, timeout=PLAYWRIGHT_TIMEOUT * 1000, wait_until=PLAYWRIGHT_WAIT_FOR)
# Optional: Wait for specific selectors (common content containers)
try:
await page.wait_for_selector("article, main, .content, #content", timeout=5000)
except:
pass # Continue if selector not found
# Get rendered HTML
html = await page.content()
# Extract markdown from rendered HTML
markdown = extract_with_trafilatura(html)
return markdown
finally:
await browser.close()
Performance Note: Playwright adds 2-5 seconds overhead. Only used when trafilatura extraction fails to meet minimum token threshold.
Token Estimation
Uses OpenAI's tiktoken library with cl100k_base encoding (same as GPT-4) for accurate context budget planning.
import tiktoken
# Initialize encoder once at startup
ENCODER = tiktoken.get_encoding("cl100k_base")
def count_tokens(text: str) -> int:
"""Count tokens using cl100k_base encoding (GPT-4 compatible)"""
return len(ENCODER.encode(text, disallowed_special=()))
Why cl100k_base? Most modern LLMs (GPT-4, Claude 3+, Gemini) use similar tokenization. cl100k_base provides conservative estimates that work across models.
Frontmatter Extraction
Extracts YAML frontmatter from markdown documents and article metadata from HTML.
import frontmatter
from bs4 import BeautifulSoup
def extract_frontmatter(markdown: str, html: str = None) -> tuple[str, dict]:
"""
Returns (markdown_without_frontmatter, metadata_dict)
"""
# Try parsing existing frontmatter
post = frontmatter.loads(markdown)
if post.metadata:
return post.content, post.metadata
# Extract from HTML metadata if available
if html:
soup = BeautifulSoup(html, 'html.parser')
metadata = {}
# OpenGraph tags
for prop in ['og:title', 'og:description', 'og:author', 'article:published_time']:
tag = soup.find('meta', property=prop)
if tag and tag.get('content'):
key = prop.split(':')[-1]
metadata[key] = tag.get('content')
# Standard meta tags
for name in ['description', 'author', 'keywords']:
tag = soup.find('meta', attrs={'name': name})
if tag and tag.get('content'):
metadata[name] = tag.get('content')
# Title
title_tag = soup.find('title')
if title_tag and 'title' not in metadata:
metadata['title'] = title_tag.get_text().strip()
if metadata:
# Prepend as YAML frontmatter
yaml_header = "---\n"
for key, value in metadata.items():
yaml_header += f"{key}: {value}\n"
yaml_header += "---\n\n"
return markdown, metadata
return markdown, {}
Redis Caching
Caches converted markdown with 1-hour TTL to avoid redundant conversions.
import redis.asyncio as redis
import json
import hashlib
async def get_cached_markdown(url: str) -> dict | None:
r = redis.from_url(os.getenv("REDIS_URL", "redis://localhost:6379"))
key = f"mdproxy:{hashlib.sha256(url.encode()).hexdigest()}"
cached = await r.get(key)
if cached:
return json.loads(cached)
return None
async def cache_markdown(url: str, result: dict):
r = redis.from_url(os.getenv("REDIS_URL", "redis://localhost:6379"))
key = f"mdproxy:{hashlib.sha256(url.encode()).hexdigest()}"
await r.setex(
key,
CACHE_TTL, # 3600 seconds default
json.dumps({
"markdown": result["markdown"],
"headers": {
"x-markdown-tokens": str(result["tokens"]),
"x-markdown-source": result["source"],
"content-signal": result["signal"]
}
})
)
Cache Invalidation: Cache is keyed by URL only (no query params). For frequently updated content, reduce CACHE_TTL or add ?nocache=true bypass parameter.
Health Check Endpoint
Reports proxy health and dependency status.
@app.get("/health")
async def health_check():
checks = {
"status": "ok",
"playwright": False,
"redis": False
}
# Test Playwright
try:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
await browser.close()
checks["playwright"] = True
except:
pass
# Test Redis
try:
r = redis.from_url(os.getenv("REDIS_URL"))
await r.ping()
checks["redis"] = True
except:
pass
return checks
4. Requirements
Core Conversion Requirements
REQ-MDPROXY-001
Conversion pipeline MUST attempt methods in order: native markdown → trafilatura → Playwright → raw HTML fallback.
REQ-MDPROXY-002
Native markdown detection MUST check URL extension (
.md,
.markdown) AND
Content-Type header (
text/markdown).
REQ-MDPROXY-003
Trafilatura extraction MUST preserve: headings, lists, tables, code blocks, links, images (with alt text).
REQ-MDPROXY-004
Playwright rendering MUST wait for
networkidle (default) or configurable wait condition (
load,
domcontentloaded).
REQ-MDPROXY-005
Token counting MUST use
tiktoken library with
cl100k_base encoding for GPT-4 compatibility.
REQ-MDPROXY-006
Minimum content threshold MUST be configurable via
MIN_CONTENT_TOKENS environment variable (default 30 tokens).
REQ-MDPROXY-007
If conversion method produces content below minimum threshold, pipeline MUST proceed to next method (no early return).
REQ-MDPROXY-008
Raw HTML fallback MUST strip
<script>,
<style>,
<noscript> tags before returning.
REQ-MDPROXY-009
All converted markdown MUST have excessive newlines collapsed (3+ consecutive → 2) and leading/trailing whitespace trimmed.
REQ-MDPROXY-010
Frontmatter extraction MUST attempt YAML parsing first, fall back to HTML
<meta> tags (OpenGraph, standard meta).
API Endpoint Requirements
REQ-MDPROXY-011
GET /{url:path} MUST extract URL from path, support both
/https://example.com and
/example.com formats.
REQ-MDPROXY-012
GET / with
Accept: text/markdown header MUST proxy to conversion pipeline (nginx integration mode).
REQ-MDPROXY-013
POST /convert MUST accept JSON body with
url (required),
timeout (optional),
wait_for (optional).
REQ-MDPROXY-014
GET /health MUST return JSON with
status,
playwright (bool),
redis (bool) fields.
REQ-MDPROXY-015
All successful responses MUST include headers:
x-markdown-tokens,
x-markdown-source,
content-signal,
x-original-url,
x-conversion-time-ms.
REQ-MDPROXY-016
Error responses MUST return HTTP 400 for invalid URLs, 408 for timeouts, 500 for conversion failures, with JSON error details.
REQ-MDPROXY-017
Response
Content-Type MUST be
text/markdown; charset=utf-8 for successful conversions.
Performance Requirements
REQ-MDPROXY-018
HTTP fetch timeout MUST be configurable via
REQUEST_TIMEOUT (default 15 seconds).
REQ-MDPROXY-019
Playwright timeout MUST be configurable via
PLAYWRIGHT_TIMEOUT (default 20 seconds).
REQ-MDPROXY-020
Maximum HTML download size MUST be enforced at
MAX_HTML_BYTES (default 5MB). Abort fetch if exceeded.
REQ-MDPROXY-021
Redis cache MUST use SHA-256 hash of URL as key with configurable TTL (default 3600 seconds).
REQ-MDPROXY-022
Cache hits MUST skip conversion pipeline and return cached markdown with original headers.
REQ-MDPROXY-023
Playwright browser instances MUST be closed after each request (no persistent browser pool).
REQ-MDPROXY-024
Conversion time MUST be measured from request start to response ready, returned in
x-conversion-time-ms header.
Security Requirements
REQ-MDPROXY-025
Server MUST bind to
127.0.0.1 by default (configurable via
BIND_HOST), not
0.0.0.0.
REQ-MDPROXY-026
URL validation MUST reject
file://,
ftp://, and non-HTTP(S) schemes.
REQ-MDPROXY-027
User-Agent header MUST be configurable via
USER_AGENT environment variable (default: modern browser UA).
REQ-MDPROXY-028
HTTP client MUST follow redirects (max 5 hops), update
x-original-url header with final URL.
REQ-MDPROXY-029
Playwright MUST disable file downloads, geolocation, notifications, and microphone/camera permissions.
REQ-MDPROXY-030
Application MUST NOT log fetched content or converted markdown (only URLs and metadata).
Content Signal Requirements
REQ-MDPROXY-031
content-signal: high MUST be set for native markdown and trafilatura conversions with ≥100 tokens.
REQ-MDPROXY-032
content-signal: medium MUST be set for Playwright conversions meeting minimum token threshold.
REQ-MDPROXY-033
content-signal: low MUST be set for raw HTML fallback or any conversion below minimum token threshold.
REQ-MDPROXY-034
If trafilatura produces ≥100 tokens,
x-markdown-source MUST be
trafilatura (not
native).
REQ-MDPROXY-035
If Playwright invoked but produces
MIN_CONTENT_TOKENS, fallback to raw HTML (do not return empty markdown).
Deployment Requirements
REQ-MDPROXY-036
Dockerfile MUST use Python 3.12 slim base image with multi-stage build for minimal size.
REQ-MDPROXY-037
Dockerfile MUST install Playwright browsers via
playwright install chromium in build stage.
REQ-MDPROXY-038
Container MUST run as non-root user with read-only filesystem except
/tmp and
~/.cache/ms-playwright.
REQ-MDPROXY-039
Docker Compose MUST include
proxy service (port 8090) and
redis service (port 6379).
REQ-MDPROXY-040
Health check MUST use
GET /health endpoint with 30-second interval for Docker HEALTHCHECK directive.