1. Problem Statement
Claude Code conversations are stateless by default. Each new conversation starts with zero context about your preferences, workflows, project history, or learned patterns. This creates three critical problems:
- Repetition fatigue: You must re-explain your coding standards, deployment scripts, test requirements, or security policies in every conversation.
- Inconsistent behavior: Without persistent instructions, Claude might use different conventions across sessions (e.g., vi vs nano, tabs vs spaces, commit message style).
- Lost institutional knowledge: Hard-won insights from debugging sessions, architecture decisions, or API gotchas evaporate when the conversation ends.
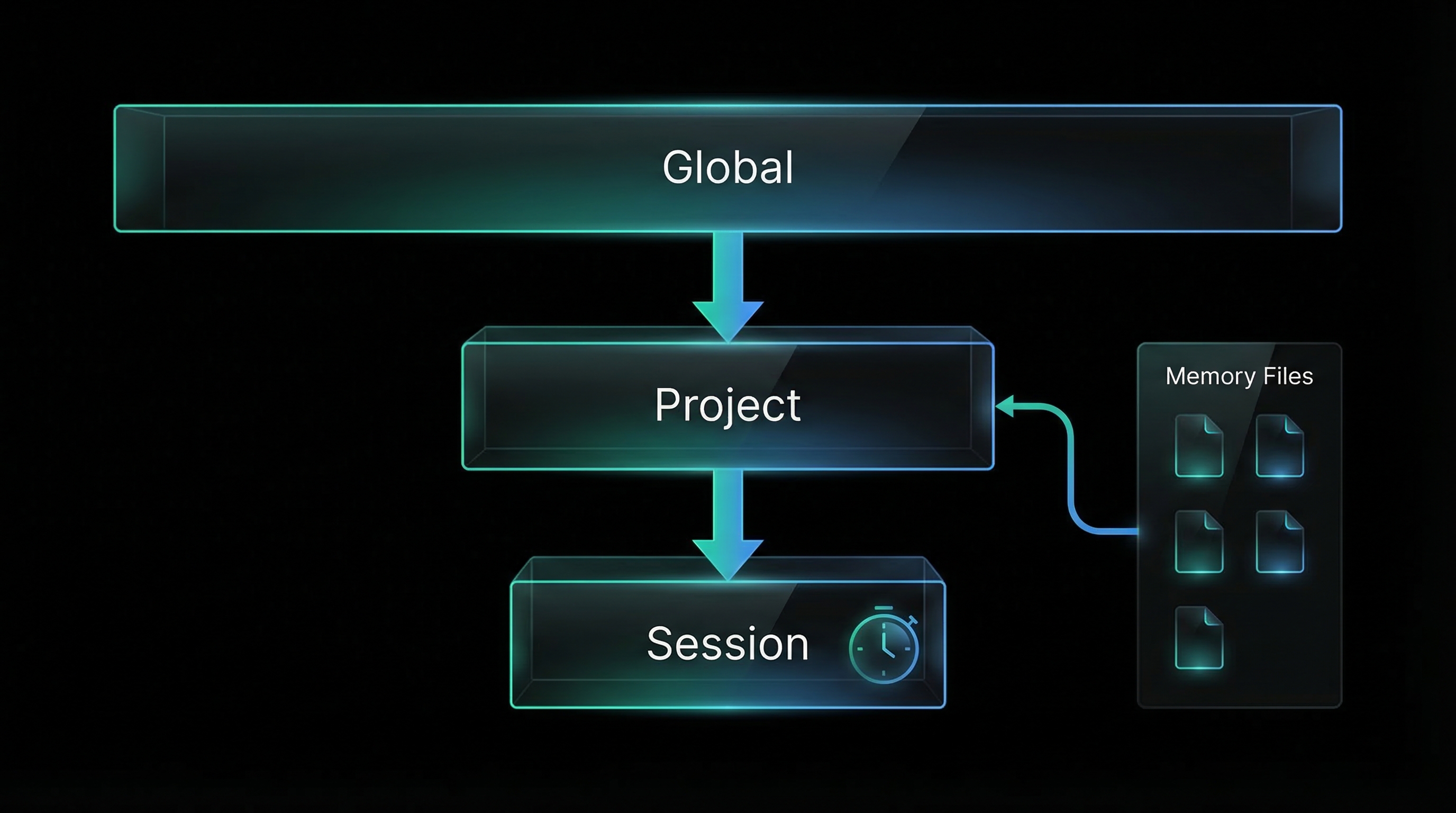
The Context Guard system solves this by establishing a three-tier instruction hierarchy:
- Global instructions (CLAUDE.md) — your personal preferences, applicable to all projects
- Project-level memory (MEMORY.md) — project-specific facts, patterns, gotchas
- Topic-specific memory (debugging.md, patterns.md) — semantic organization of specialized knowledge
This is NOT a vector database. This is NOT about semantic search. This is about explicit, enforced, persistent instructions that load into every conversation and override default behavior.
2. Architecture Overview
3. Key Components
3.1 Global Instructions (CLAUDE.md)
The ~/.claude/CLAUDE.md file contains user-level preferences and enforced rules. This file is loaded into every conversation regardless of project or directory.
What belongs here:
- Editor preferences (vi, not nano)
- Code quality standards (no console.log in production, no TODO comments)
- Security policies (no hardcoded credentials, validate all inputs)
- Git workflow rules (never force push to main/master, require linear history)
- Communication style (direct, no fluff, challenge when wrong)
- Testing requirements (before finishing ANY task, verify it works)
- Documentation standards (no unsolicited README.md files)
Enforced rules pattern:
Use ENFORCED or CRITICAL tags to override default behavior:
## Code Standards (ENFORCED)
- No placeholder code or stubs. Full production code only.
- No hardcoded secrets. Use environment variables.
- No arbitrary code execution with user input.
- No `git add .` without review. Stage specific files.
## Privacy (CRITICAL)
NEVER include: employer name, job title, certifications, or identifying info.
Reference frameworks (NIST, ISO 27001) not credentials.Why this works: The ENFORCED tag signals high priority. Claude Code's instruction parser treats these as hard constraints, not suggestions.
3.2 Project-Level Memory (MEMORY.md)
Each project gets a hashed directory under ~/.claude/projects/. The hash is computed from the project's absolute path to ensure uniqueness.
Path structure:
~/.claude/projects/-Users-user-Documents-Code-myapp/
├── memory/
│ ├── MEMORY.md # Main index (always loaded)
│ ├── debugging.md # Topic: debugging patterns
│ ├── patterns.md # Topic: reusable patterns
│ └── audit-history.md # Session-by-session notesWhat belongs in MEMORY.md:
- Schema gotchas: Field names that differ from conventions (
users.firstNamenotdisplayName) - API patterns: Authentication helper signatures, pagination logic, error handling
- Test infrastructure: Mocking patterns, test helper locations, coverage requirements
- Build notes: Next.js config quirks, Docker healthchecks, ESLint flat config
- Known limitations: Technical debt, deferred work, planned migrations
- Stats: Line counts, test counts, coverage percentages (snapshot at last session)
Example MEMORY.md excerpt:
## Schema Facts (error-prone)
- `users.firstName` (NOT `displayName`)
- `agents` table: `createdBy`/`ownedBy` (NOT `ownerId`)
- `testRunStatusEnum`: `pending | running | completed | failed | cancelled` (NO `passed`)
## API Patterns
- `authenticateRequest(request)` → `AuthenticatedRequest | NextResponse`
- `requirePermission(authResult, 'resource.action')` → `null | NextResponse`
- `paginatedResponse(data, total, params)` — 3 args
- ILIKE escape: `search.replace(/[%_\\]/g, '\\$&')`
## Gotchas (error-prone patterns)
- Drizzle `gt(column, value)` NOT `gt(value, column)` — column always first
- Every PATCH handler needs Zod validation — never destructure raw body
- ALL UPDATE/DELETE WHERE clauses include `organizationId` (TOCTOU prevention)Why this works: The next time you ask Claude to "add a new API route," it will automatically apply your auth pattern, pagination logic, and error handling conventions without being told.
3.3 Topic-Specific Memory Files
As projects grow, MEMORY.md becomes unwieldy. Break specialized knowledge into topic files:
debugging.md— stack trace patterns, error resolutions, flaky test fixespatterns.md— authentication flows, rate limiting, SSRF preventiondeployment.md— Docker compose configs, healthcheck patterns, secret managementtesting.md— mock patterns, snapshot strategies, integration test setup
Reference pattern in MEMORY.md:
## Extended Documentation
See topic-specific memory files:
- `debugging.md` — error resolution history
- `patterns.md` — reusable authentication/security patterns
- `deployment.md` — Docker stack configurationClaude Code will auto-load referenced files when they're mentioned in MEMORY.md or when you explicitly ask about a topic.
3.4 Context Compression (PreCompact Hook)
Long conversations hit Claude's context window limit. The PreCompact hook runs before compression and saves ephemeral context to MEMORY.md.
What gets saved:
- New schema facts discovered during the session
- Error resolution patterns that worked
- Performance optimizations applied
- Security fixes and their rationale
- Updated stats (test counts, coverage, line counts)
What does NOT get saved:
- Exploratory debugging commands
- Draft code that was rejected
- Tangential discussions unrelated to the project
- Temporary workarounds that were later replaced
This is a manual process. At the end of a productive session, you run /memory-save to append new learnings to MEMORY.md.
4. Requirements
The system MUST load ~/.claude/CLAUDE.md into every conversation at session start, regardless of project or working directory.
The system MUST compute a deterministic hash from the project's absolute path using base64url(sha256(path)) to create a unique project identifier.
The system MUST load ~/.claude/projects/<hash>/memory/MEMORY.md (if it exists) after loading CLAUDE.md.
When conflicting instructions exist, the system MUST prioritize: (1) CLAUDE.md ENFORCED rules, (2) project MEMORY.md, (3) session-level context, (4) Claude defaults.
The system MUST treat sections tagged with ENFORCED or CRITICAL as hard constraints that override default behavior.
If MEMORY.md references topic files (e.g., "See debugging.md"), the system SHOULD load those files when the topic becomes relevant in conversation.
The system MUST provide a /memory-save command that appends new learnings from the current session to MEMORY.md with a timestamp.
The system MUST provide a /memory-resume command that re-loads CLAUDE.md and MEMORY.md mid-conversation to pick up external edits.
The system MUST trigger a PreCompact hook before compressing conversation history, allowing plugins to save ephemeral context to persistent storage.
The system MUST NOT auto-create MEMORY.md files. Users explicitly create them when a project warrants persistent context.
If CLAUDE.md contains privacy rules (e.g., "NEVER include employer name"), the system MUST enforce these rules when generating MEMORY.md updates.
MEMORY.md SHOULD be organized by topic (schema, API patterns, gotchas) NOT chronologically. Session-by-session notes belong in a separate audit-history.md file.
5. Prompt to Build It
I need to build a Context Guard system for Claude Code that provides hierarchical, persistent instructions across conversations. Here's what I need:
## Core Functionality
1. **Global instructions (CLAUDE.md)**:
- Create ~/.claude/CLAUDE.md that loads into EVERY conversation
- Support ENFORCED/CRITICAL tags for hard constraints
- Sections: Core Behavior, Code Standards, Privacy Rules, Git Workflow, Testing Requirements
2. **Project-level memory (MEMORY.md)**:
- Compute project hash: base64url(sha256(absolute_path))
- Auto-create directory: ~/.claude/projects//memory/
- Load MEMORY.md at session start (if exists)
- Sections: Schema Facts, API Patterns, Gotchas, Build Notes, Stats
3. **Topic files**:
- Support references like "See debugging.md" in MEMORY.md
- Auto-load topic files when mentioned or when topic becomes relevant
- Suggested topics: debugging.md, patterns.md, deployment.md, testing.md
4. **Session commands**:
- /memory-save — append new learnings to MEMORY.md with timestamp
- /memory-resume — reload CLAUDE.md + MEMORY.md mid-conversation
- /memory-stats — show loaded files and instruction count
5. **PreCompact hook**:
- Trigger before conversation compression
- Extract: schema facts, error resolutions, performance optimizations, security fixes
- Skip: exploratory commands, rejected drafts, temporary workarounds
## Instruction Priority
(1) CLAUDE.md ENFORCED rules
(2) MEMORY.md project facts
(3) Session context
(4) Claude defaults
## Privacy Enforcement
If CLAUDE.md has privacy rules (e.g., "NEVER include employer name"), enforce them when generating MEMORY.md updates.
## Semantic Organization
MEMORY.md organized by topic, NOT chronologically. Session notes go in audit-history.md.
Build this system with:
- Bash script for hash computation and directory setup
- Hook implementation for PreCompact and SessionStart
- Commands for /memory-save, /memory-resume, /memory-stats
- Markdown template for CLAUDE.md and MEMORY.md
Start with the project hash computation script and SessionStart hook. 6. Design Decisions
6.1 Why Three Tiers?
Decision: Use global (CLAUDE.md), project (MEMORY.md), and session context instead of a flat single-file approach.
Rationale:
- Global rules (vi, no stubs) apply to ALL projects. Repeating them in every MEMORY.md creates maintenance burden.
- Project rules (schema gotchas, API patterns) are irrelevant to other projects. Polluting global context hurts clarity.
- Session context (active task, current edits) is ephemeral and shouldn't persist across conversations.
Trade-off: More complexity in the load sequence, but dramatically better context relevance and maintainability.
6.2 Why Hashed Project Paths?
Decision: Use base64url(sha256(path)) instead of human-readable project names.
Rationale:
- Absolute paths are unique. Project names are not ("api", "frontend", "backend" exist in many repos).
- Hashing handles special characters, spaces, and Unicode without filesystem issues.
- Deterministic hashing means moving a project breaks the link. This is a feature — MEMORY.md is path-specific.
Trade-off: Directories are not human-readable. Solution: MEMORY.md includes a header with the original path for reference.
6.3 Why NOT Auto-Create MEMORY.md?
Decision: Require users to explicitly create MEMORY.md files. No auto-generation.
Rationale:
- Not every project warrants persistent memory. One-off scripts don't need MEMORY.md.
- Auto-creation leads to clutter (hundreds of empty MEMORY.md files for throwaway projects).
- Explicit creation signals intent: "This project is important enough to track context."
Trade-off: Users must remember to create MEMORY.md for new projects. Mitigated with a /memory-init command.
6.4 Why Semantic Organization?
Decision: Organize MEMORY.md by topic (schema, API patterns, gotchas) instead of chronologically (session 1, session 2, session 3).
Rationale:
- Claude searches for relevant facts, not timestamps. "What's the auth pattern?" needs to find the API section, not dig through session logs.
- Chronological organization creates duplication (same fact updated across multiple sessions).
- Topic organization enables incremental refinement (add a new gotcha to the Gotchas section, don't append to session 27).
Trade-off: Harder to audit "what changed when." Solution: Maintain a separate audit-history.md for session-by-session notes.
6.5 Why Manual /memory-save?
Decision: Require users to run /memory-save instead of auto-saving after every conversation.
Rationale:
- Not every conversation produces valuable learnings. Auto-save pollutes MEMORY.md with noise.
- Users know which sessions were productive. Manual save is a deliberate act of curation.
- Auto-save risks committing incorrect facts (e.g., a debugging dead-end that was later disproven).
Trade-off: Users might forget to save. Mitigated with an end-of-session reminder if new learnings were detected.
7. Integration Points
7.1 Vector Memory System
Context Guard (CLAUDE.md + MEMORY.md) provides explicit, structured instructions. The Vector Memory System provides semantic search across unstructured learnings.
How they work together:
- MEMORY.md stores high-value, curated facts that should ALWAYS load (schema gotchas, API patterns).
- Vector memory stores lower-priority learnings that load on-demand via semantic search (debugging history, performance experiments).
- PreCompact hook can save to BOTH: critical facts → MEMORY.md, contextual learnings → vector database.
Example: "Never use gt(value, column) in Drizzle" goes in MEMORY.md. "Optimized query performance by adding index on user_id" goes in vector memory.
7.2 Conductor Plugin
The Conductor plugin orchestrates multi-agent workflows. It reads CLAUDE.md to understand user preferences for agent selection.
Integration:
- CLAUDE.md contains a "Preferred Agents" section listing domain-specific agents (e.g., "For security reviews, use ciso agent").
- Conductor reads this section at session start and prioritizes those agents in its dispatch logic.
- If MEMORY.md mentions recurring tasks (e.g., "API reviews always check rate limiting"), Conductor can auto-invoke the right agent.
7.3 Governance Plugin
The Governance plugin enforces approval gates and data classification rules. It reads CLAUDE.md for privacy policies.
Integration:
- CLAUDE.md contains a "Privacy (CRITICAL)" section with redaction rules.
- Governance plugin loads these rules at session start and applies them to ALL outputs (including MEMORY.md updates).
- When generating content for external communication, Governance checks CLAUDE.md for approval gate requirements.
7.4 Skill System
Skills can reference CLAUDE.md for user-specific overrides (e.g., "Use user's preferred cloud provider for deployment").
Integration:
- Skills check CLAUDE.md for override patterns (e.g., "Preferred cloud: AWS" vs "Preferred cloud: GCP").
- MEMORY.md can list skill-specific facts (e.g., "For PDF generation, always use 11pt font, not 12pt").
- Skills can write back to MEMORY.md after successful execution (e.g., "Last deployment: 2026-03-15, 3.2s build time").
7.5 Hook System
The Context Guard system relies on two hooks:
- SessionStart: Loads CLAUDE.md, computes project hash, loads MEMORY.md and topic files.
- PreCompact: Before conversation compression, extracts new learnings and prompts user to save them to MEMORY.md.
Other plugins can also register PreCompact hooks to save domain-specific context (e.g., test results, deployment logs).